
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- HostPath
- EKS vLLM
- k8s scheduler
- eksctl
- pv/pvc
- Node group
- Instance Store
- cni binary
- aws vpc cni
- auto mode
- CoreDNS
- aws-node
- soci
- EKS Architecture
- hashicorp
- ipamd
- EKS
- serviceaccount
- Terraform
- gateway api
- ClusterIP
- nodeport
- 쿠버네티스 네트워크
- kube-proxy
- Fargate
- EmptyDir
- kubernetes networking
- k8s authentication
- eks upgrade
- externaldns
- Today
- Total
ksc0204 님의 블로그
AEWS 4기 5주차(2) - 워커노드 kubelet,containerd 디버깅, Loadbalancer 트러블슈팅 본문
before start..
주관적인 해석이 포함되어 있어 사실과 다르거나 오류가 있을 수 있으니 참고용으로만 읽어주시기 바랍니다.
Node 레벨 디버깅
노드 조인 실패 디버깅
노드 조인이란? 워커 노드가 작업을 수행하기 위해 클러스터에 등록되는 것을 의미하며, 아래와 같이 노드 조인이 실패하는 일반적인 원인이 발생할 수 있습니다.
- aws-auth ConfigMap에 노드 IAM Role이 등록되지 않음 (또는 Access Entry 미생성) — 노드가 API 서버에 인증할 수 없음
- 부트스트랩 스크립트의 ClusterName이 실제 클러스터명과 불일치 — kubelet이 잘못된 클러스터에 연결 시도
- 노드 보안그룹이 컨트롤 플레인과의 통신을 허용하지 않음 — TCP 443 (API 서버), TCP 10250 (kubelet) 포트가 필요
- 퍼블릭 서브넷에서 auto-assign public IP가 비활성화됨 — 퍼블릭 엔드포인트만 활성화된 클러스터에서 인터넷 접근 불가
- VPC DNS 설정 문제 — enableDnsHostnames, enableDnsSupport가 비활성화됨
- STS 리전 엔드포인트가 비활성화됨 — IAM 인증 시 STS 호출 실패
- 인스턴스 프로파일 ARN을 노드 IAM Role ARN 대신 aws-auth에 등록 — aws-auth에는 Role ARN만 등록해야 함
- eks:kubernetes.io/cluster-name 태그 누락 (자체관리형 노드) — EKS가 노드를 클러스터 소속으로 인식하지 못함
노드 조인 실패 - 진단 명령어
# 노드 부트스트랩 로그 확인 (SSM 접속 후)
sudo journalctl -u kubelet --no-pager | tail -50
sudo cat /var/log/cloud-init-output.log | tail -50
# 보안그룹 규칙 확인
aws ec2 describe-security-groups --group-ids $CLUSTER_SG \
--query 'SecurityGroups[].IpPermissions' --output table
# VPC DNS 설정 확인
aws ec2 describe-vpc-attribute --vpc-id $VPC_ID --attribute enableDnsHostnames
aws ec2 describe-vpc-attribute --vpc-id $VPC_ID --attribute enableDnsSupport
EKS - Node Group 장애 확인
워커 노드 - EC2 인스턴스 중지
AWS 콘솔에서 노드 그룹에 속해 있는 EC2 인스턴스를 중지시킬 경우 노드그룹에서는 해당 노드를 제외하고 신규 노드를 생성하여 노드그룹으로 할당시킵니다.



워커 노드 - kubelet 중지

3.35.6.3 IP를 사용 중인 노드그룹에서 kubelet을 중지 이후 노드 상태를 확인 시 NotReady 상태를 확인할 수 있습니다.

노드 상태에 대해서 상세한 내용 확인(kubectl describe node <node 명>)하였을 때 kubelet이 중지되었다는 것을 확인할 수 있는 것을 확인하였습니다.

이후 kubelet 서비스를 기동하였고 노드는 정상 상태로 돌아오는 것을 확인할 수 있습니다.


워커 노드 - containerd 중지


이번에도 Node 상태가 NotReady 상태로 변하였지만 Condition에서는 이상 징후는 없다.

다만, 이벤트 항목에서 확인 시 'rpc error: code = Unabailable desc = connection error: desc "transport: Error while dialing: dial unix /run/containerd/containerd.sock: connect: no such file or directory"라는 에러가 발생하는 것을 확인할 수 있습니다.

워커 노드 - Memory Pressure

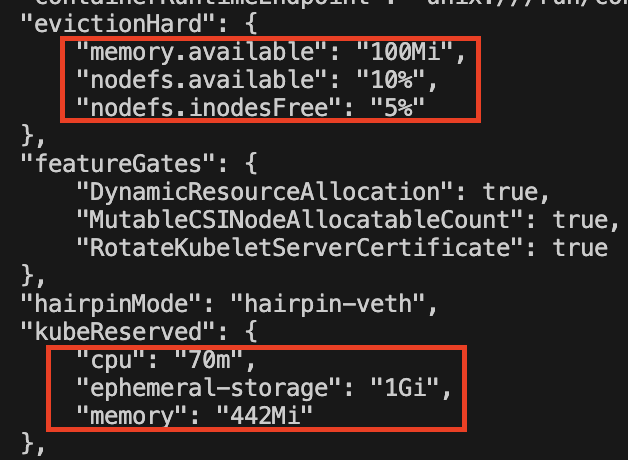
현재 워커노드에서 설정된 Memory Pressure 설정은 위 이미지에 evictionHard에 대한 내용입니다.
- memory.available: 노드의 가용 메모리가 100MiB 미만으로 떨어지는 순간, Kubelet은 즉시 해당 노드에 MemoryPressure 조건을 True로 변경합니다.
- 이 상태가 되면 Kubelet은 노드를 보호하기 위해 우선순위가 낮은 Pod부터 강제 종료(Eviction)시키기 시작합니다.
추가로, kubeReserved에 대한 설정입니다.
- memory": "442Mi": Kubelet이나 OS 커널 등 시스템 인프라가 안정적으로 돌아가기 위해 미리 예약해둔 메모리입니다.
- 즉, 전체 메모리 용량에서 이 442Mi를 뺀 나머지가 Pod들이 나눠 쓸 수 있는 공간이 됩니다.
kubeReserved란? 쿠버네티스 시스템 컴포넌트들을 위해 미리 떼어둔 예약 리소스입니다.
쿠버네티스 노드 위에는 사용자의 Pod뿐만 아니라, 클러스터를 관리하는 핵심 프로세스들(kubelet, container runtime 등)도 함께 돌아갑니다.
만약, 사용자의 Pod가 노드의 메모리나 CPU를 100% 다 써버리면, 정작 노드를 관리해야 할 kubelet이 죽어버려 노드 전체가 제어 불능(NotReady) 상태가 될 수 있습니다.
이를 방지하기 위해 리소스를 미리 예약해둔 설정입니다.
Memory Stress 부하를 주는 Deployment를 배포하여 특정 리소스를 사용할 때 어떤 현상이 벌어지는지 확인하였습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: memory-stress-test
labels:
app: memory-stress
spec:
replicas: 1
selector:
matchLabels:
app: memory-stress
template:
metadata:
labels:
app: memory-stress
spec:
containers:
- name: stress-ng
image: polinux/stress-ng
# 실제 메모리를 점유할 명령어를 추가해야 합니다.
args: ["--vm", "1", "--vm-bytes", "800M", "--vm-hang", "0"]
resources:
requests:
memory: "800Mi"
# limits를 크게 잡거나 제거해야 노드 레벨의 압박 테스트가 가능합니다.
limits:
memory: "2Gi"
terminationGracePeriodSeconds: 0위와 같이, 디플로이먼트 선언 후

Replicas 증가(1 > 8)




에러메시지(FailedScheduling)
- 1 Insufficient memory: 노드 한 곳은 메모리가 부족해서 Pod를 더 이상 받을 수 없습니다. 현재 Deployment에서 requests를 2Gi로 설정하셨기 때문에, 해당 노드에 남은 여유 메모리가 2Gi보다 적으면 이 메시지가 뜹니다.
- 1 node(s) didn't match Pod's node affinity/selector: 다른 노드 한 곳은 아까 설정하신 nodeSelector 조건(특정 호스트네임)과 맞지 않아서 후보에서 제외되었습니다.

추가로, 메모리 압박 테스트 중에 발생할 수 있는 전형적인 네트워크 IP 부족 및 OOM(Out of Memory) 재시작 현상입니다.

위 에러에서는 aws-cni Pod에서 IP Address를 할당 받지 못하여 장애 발생하게 되었습니다.
1. FailedCreatePodSandBox(네트워크 IP 부족)
Message: failed to assign an IP address to container
- 원인: EKS에서 사용하는 aws-node (VPC CNI)가 해당 노드에 할당할 수 있는 Private IP를 모두 소모했습니다.
- 상세 이유: AWS의 각 인스턴스 타입(예: t3.medium)은 붙일 수 있는 네트워크 인터페이스(ENI)와 IP 개수가 제한되어 있습니다. 메모리 테스트를 위해 replicas를 과하게 늘리다 보면, 메모리가 차기 전에 IP가 먼저 고갈되어 더 이상 Pod를 생성하지 못하는 상태가 됩니다.
2. BackOff(컨테이너 무한 재시작)
Message: Back-off restarting failed container stress-ng
- 원인: 컨테이너가 실행되자마자 OOMKilled 되어 죽고, 쿠버네티스가 다시 살리기를 반복하다가 결국 "잠시 쉬었다가 살릴게"라며 포기한 상태입니다.
- 상세 원인 :
케이스 A - YAML의 resources.limits.memory 설정보다 args의 --vm-bytes가 더 큽니다. (예: 제한은 1G인데 2G를 쓰라고 명령함)
케이스 B - 노드 전체 메모리가 이미 바닥나서 커널이 새로 뜨는 컨테이너를 즉시 죽여버리고 있습니다.
EKS에서 로드밸런서를 생성이 필요한 경우 아래와 같은 절차가 필요하다.(IRSA 기준)
IAM 역할(로드밸런서 제어) 생성 > IRSA 생성 > LB 컨트롤러 Pod 생성(Helm 배포) > Loadbalancer 프로비저닝
즉, Loadbalancer에서는 위 절차에서 생략되는 과정이 있거나 IAM 역할에서 로드밸런서에 대한 제어 권한이 없을 경우 로드밸런서 생성 및 제어가 불가능할 수 있습니다.
Action 1. LB컨트롤러 Pod가 배포되지 않았을 때 LB를 프로비저닝한 경우
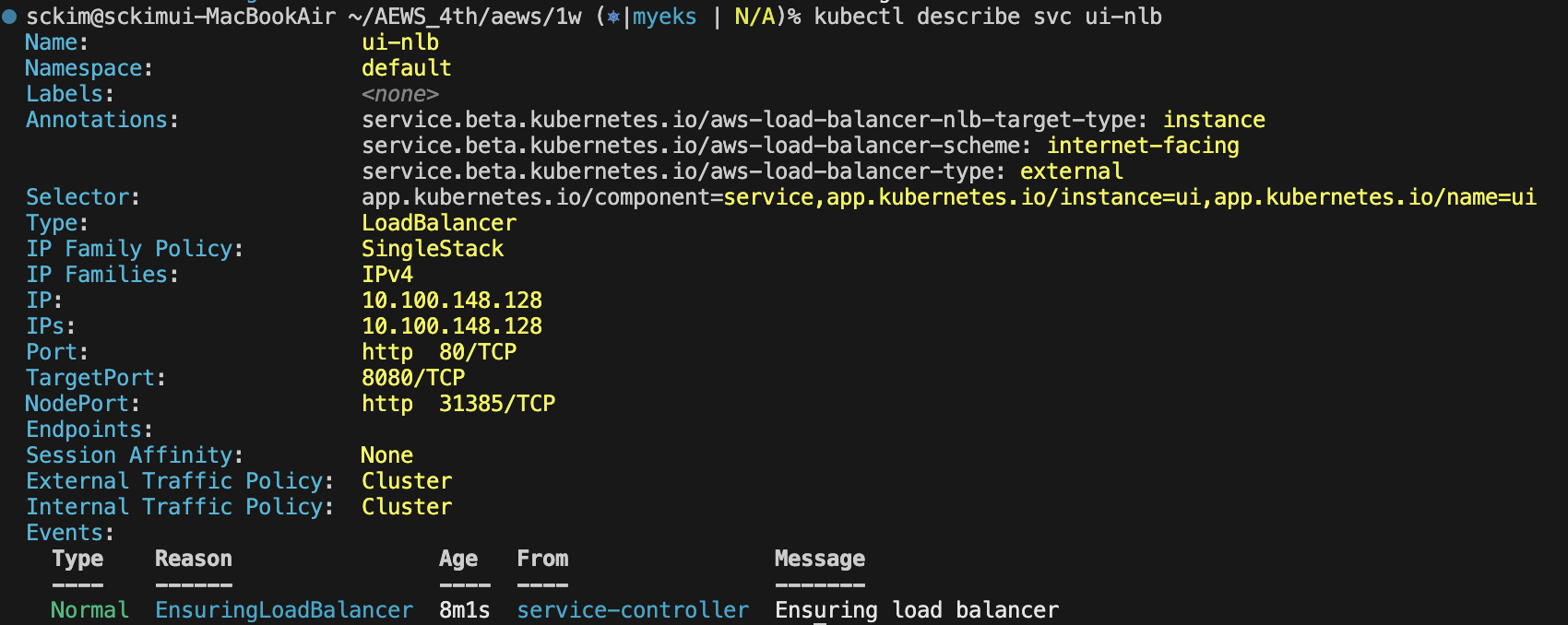
어떠한 설정 없이 NLB를 아래와 같이 배포하였습니다.

다만, 몇 분이 지나더라도 AWS에서 Loadbalancer가 생성되지 않고 있으며, EXTERNAL-IP도 지속해서 Pending 상태로 확인할 수 있습니다.

Action 2. IAM 역할이 잘못 설정되어 있을 경우
LB 컨트롤러에서 사용하기 위해서 IRSA에 사용하는 정책(policy)에 대해서 로드밸런서 및 타겟그룹에 대한 생성 권한을 사용하지 않고 IRSA를 생성하여 LB 컨트롤러에서 사용할 경우 로드밸런서가 배포되는지 확인

# 로드밸런서 및 타겟그룹 생성 정책이 빠진 역할을 통해 IRSA 생성
eksctl create iamserviceaccount \
--cluster=$CLUSTER_NAME \
--namespace=kube-system \
--name=aws-load-balancer-controller \
--attach-policy-arn=arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy2 \
--override-existing-serviceaccounts \
--approve
# LBC 배포
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --version 3.1.0 \
--set clusterName=myeks \
--set serviceAccount.name=aws-load-balancer-controller \
--set serviceAccount.create=false \
--set region=ap-northeast-2 \
--set vpcId=vpc-xxxxxxxxxxxx
아까와 동일하게 nlb.yaml이라는 네트워크 로드밸런서를 배포하였을 때 이번에는 describe로 조회 시 LB 및 타겟그룹에 대한 생성 권한이 확인되지 않아 FailedDeployModel이 발생하는 것을 확인할 수 있습니다.

다시 기존 IAM 정책에 로드밸런서와 타겟그룹을 생성하는 권한을 설정한 뒤 NLB를 프로비저닝하였고 정상적으로 배포되는 것을 확인할 수 있습니다. 추후에, LB 프로비저닝 시 IAM 역할이 잘못설정된 경우 권한만 추가해주거나 삭제하면 반영되오니 LB 컨트롤러 Pod를 재배포하거나 삭제할 필요가 없습니다.



'AWS 4기' 카테고리의 다른 글
| AEWS 4기 6주차(2) - EKS CI/CD(Flux CD + Helm Chart) (0) | 2026.04.23 |
|---|---|
| AEWS 4기 6주차(1) - EKS CI/CD(flux cd, tofu-controller) (0) | 2026.04.22 |
| AEWS 4기 5주차(1) - EKS Debuggig(k8s debugging) (0) | 2026.04.18 |
| AEWS 4기 4주차(3) - EKS 인증/인가 실습, IRSA, Pod-identity (0) | 2026.04.12 |
| AEWS 4기 4주차(2) - EKS 인증/인가(kubectl 동작 방식) (0) | 2026.04.12 |

